Avec les Google Cloud Functions, la tache est simplifiée pour importer des données dans une table BigQuery.
Avec les librairies Python de Google, il est facile de faire les etapes d’authentification (avec secretmanager) et les configurations pour l’environnement BigQuery (via client).
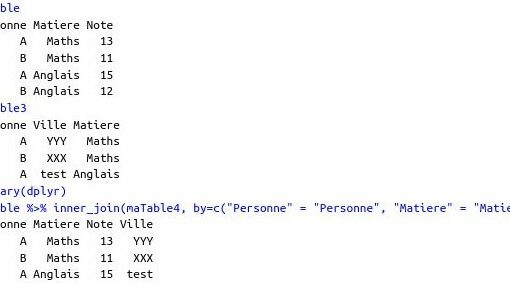
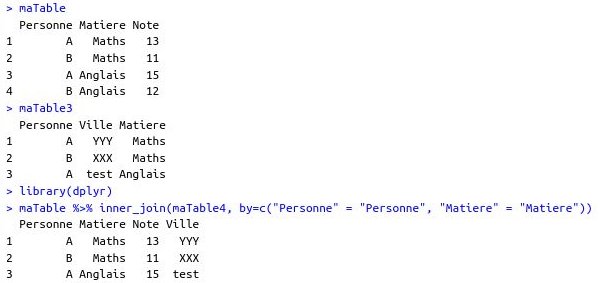
Il s’agit ensuite de définir le dataset dans lequel se trouve la table BigQuery ciblée pour importer dedans les données du dataframe (via client.load_table_from_dataframe).
Il est recommandé de passer par un dataframe car cela permet de facilement restructurer les données si besoin (c’est mieux de le faire des le départ pour anticiper un futur besoin).
Code d’exemple :
import functions_framework
from google.cloud import bigquery
from google.oauth2 import service_account
from google.cloud import secretmanager
#print('-- Secret Manager client')
client = secretmanager.SecretManagerServiceClient()
response = client.access_secret_version(request={"name": "projects/" + info_secret_projetId + "/secrets/" + info_secret_id + "/versions/" + info_secret_version })
#print('-- Credentials pour info de connexion au compte BigQuery')
credentials = service_account.Credentials.from_service_account_info(json.loads(response.payload.data.decode("UTF-8")))
#print('-- Client pour la connexion a BigQuery')
client = bigquery.Client(credentials= credentials,project=info_projet)
#print('-- dataset_id pour le nom du dataset')
dataset_id = info_dataset
#print('-- dataset_ref pour cibler le dataset dans le compte BigQuery')
dataset_ref = client.dataset(dataset_id)
#print('-- job_config pour la configuration de la tache d import des donnees')
job_config = bigquery.LoadJobConfig()
#print('-- Compilation des infos pour configuration de l import ')
job = client.load_table_from_dataframe(
df,
dataset_ref.table(info_table),
job_config=job_config
)
#print('-- Execution de l import dans BigQuery')
job.result()


{kind=link}