Pour charger un fichier csv dans un dataframe, il est possible d’utiliser la librairie pandas. Cette librairie permet notamment de définir le type de chaque colonne lors de la création du dataframe (via pandas.read_csv).
Avec les dataframes, il est ensuite facile de changer les noms de colonnes si besoin (pour compatibilité avec d’autres environnements).
Code d’exemple :
import pandas
#print('-- infos sur les colonnes et leur typage pour eviter des erreurs')
colonnes_type = {
'{app_name}' : 'str',
'{click_time_hour}' : 'Int64'
}
#print('-- chargement des donnees dans un dataframe)
df = pandas.read_csv(blob_decompress, dtype= colonnes_type )
#print('-- Remise en place du bon typage des champs dans le dataframe')
df = df.astype(colonnes_type)
#print('-- Renommage des intitules de colonnes du dataframe pour compatibilite avec BigQuery')
colonnes_nouveau_nom = {
'{app_name}' : 'app_name',
'{click_time_hour}' : 'click_time_hour'
}
df = df.rename(columns=colonnes_nouveau_nom)
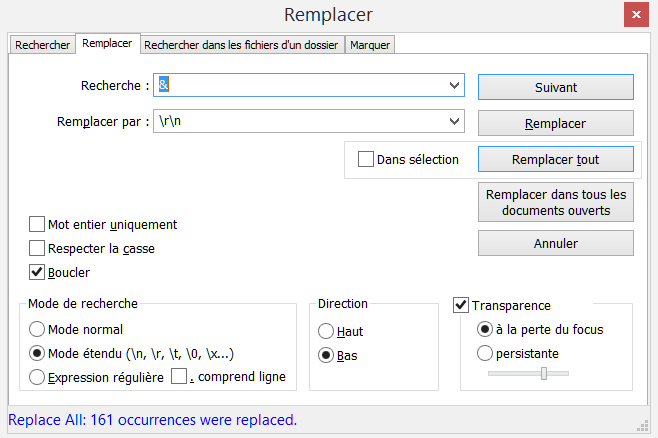
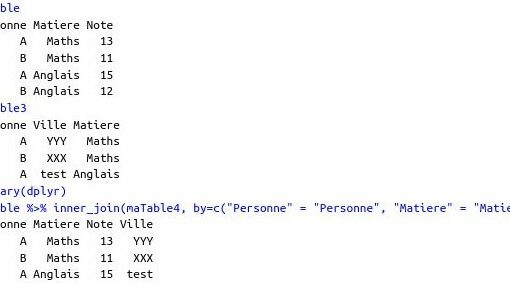
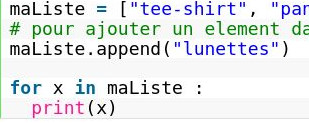
{kind=link}
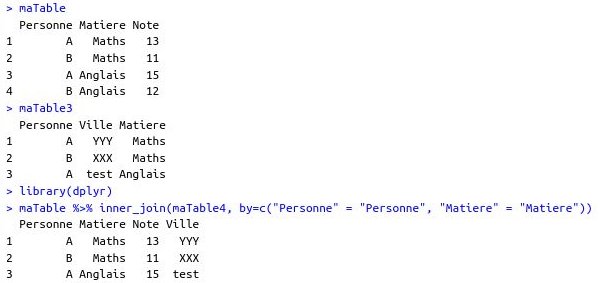{kind=link}