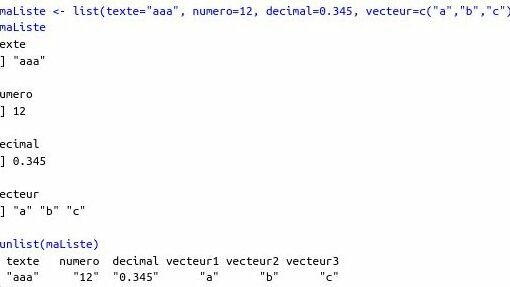
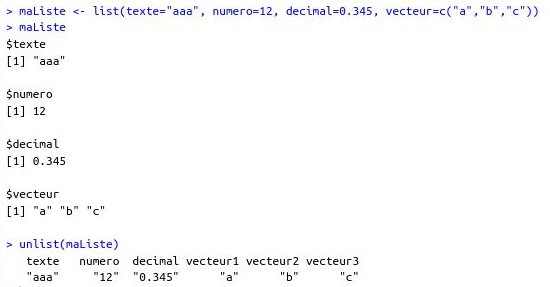
La librairie dplyr facilite la manipulation des données. Elle permet notamment de faire des « chainages », c’est à dire d’ecrire son code en faisant référence à des séquences de fonctions à executer les unes après les autres, ceci facilite l’ecriture (en évitant de faire des combinaisons impliquant des « retours en arrière »), ainsi que la lecture et donc la maintenance du code.
Par exemple, si on travaille avec le data frame suivant :
data <- data.frame(v1=c("a","b","c","a","b","c"), v2=c(1,2,3,4,5,6))
| v1 | v2 |
| a | 1 |
| b | 2 |
| c | 3 |
| a | 4 |
| b | 5 |
| c | 6 |
Si on souhaite connaitre la moyenne de v2 pour chaque valeur de v1, il est possible de le faire en combinant les fonctions group_by() et summarise()
summarise( group_by(data,v1), v2= mean(v2))
Mais cette manière d’écrire le code n’est pas pratique. Car on doit commencer par la fonction summarise() qui est celle qui correspond à la 2eme étape du calcul (la premiere etape du calcul étant celle avec group_by). Cela demande donc une gymnastique mentale (commencer par l’etape 2, puis mettre l’etape 1) qui peut être source d’erreur.
Avec les chainages que permet la librairie dplyr, il n’y a pas besoin de faire cette gymnastique mentale. On peut décomposer le calcul par étape dans l’ordre « naturel ». Chaque étape est séparée par le terme « %>% » et l’etape suivante reprend le résultat du calcul précédent comme premier paramètre dans la fonction appelée.
data %>% group_by(v1) %>% summarise(v2=mean(v2))
On visualise ainsi mieux les étapes du calcul et elles se lisent bien les unes apres les autres (au lieu d’être imbriquées les unes dans les autres). Cette méthodologie est très utile notamment quand il y a plus d’etapes (car plus il y a d’etapes, plus les imbrications deviennent compliquées à gérer).

Pour + d’infos :


{kind=link}
{kind=link}