Lors d’un précédent article, on avait parlé d’une méthode pour générer une visualisation en soleil (sunburst) avec les données de Google Analytics (via Big Query) : https://www.webanalytix.fr/comment-visualiser-les-parcours-de-google-analytics-avec-un-sunburst-via-r/
Cette méthode s’applique très bien aussi pour une analyse avec les données de Piano Analytics. C’est ce que nous allons voir avec cet article.
Pourquoi génerer une visualisation en soleil des données de navigation de Piano Analytics ?
Piano Analytics a nativement des rapports pour visualiser la navigation des internautes (menu « Navigation »). Dans ces rapports natifs, on retrouve une visualisation en soleil (similaire à celle que l’on retrouve aussi dans ContentSquare), ainsi qu’un diagramme des fluxs. Ils permettent une lecture plus rapide des parcours principaux. Mais ces rapports sont basés uniquement sur la variable « Page ».
La valeur ajoutée de la visualisation générée via R dans cet article est :
- La possibilité de travailler avec n’importe quelle variable (pas que les pages, mais aussi les evenements, les infos Produits ou les bannières d’autopromotion, etc)
- Une personnalisation plus avancée (notamment pour voir plus d’etapes si besoin)
- Un format de visualisation interactive qui se partage plus facilement
La méthode
La méthode va être expliquée à partir de fausses données permettant de visualiser des parcours menant à une page Panier virtuelle. Ces fausses données sont disponibles en bas de l’article, ainsi que les scripts R utilisés.
Les grandes étapes sont :
- 1 – Récupération des données souhaitées dans Piano Analytics (via Data Query)
- 2 – Définition des paramètres de l’analyse (dans un fichier JSON qui sera exploité par R)
- 3 – Execution des scripts R – Transformation des données pour répondre à la demande avec une structure compatible avec une visualisation en soleil (via R)
- 4 – Execution ds scripts R – Génération de la visualisation en soleil à partir des données transformées
Etape 1 : Récupération des données souhaitées dans Piano Analytics
Les données à récupérer avec Data Query sont :
- L’id de session (« ID Visite » dans le langage Piano, il peut etre combiné avec l’ID Visiteur)
- La position du hit dans la session (« Position évènement » dans le langage Piano)
- La variable à étudier (par défaut, ca peut être le nom de page ou le nom des produits ou le nom des bannières autopromotion, etc)
Pour récupérer ces données, un segment peut être appliqué pour cibler uniquement les visites souhaitées (par exemple celles étant passés par une page donnée).
Dans Data Query, ces données peuvent être exportées en utilisant l’option « Exporter les données (GZIP) » (pour décompresser le fichier gzip, il est possible d’utiliser 7-zip qui est libre et gratuit). Cette option permet d’avoir des millions de lignes dans 1 seul fichier. Le fichier récupéré sera un fichier csv (fichier texte avec la virgule comme separateur).
Etape 2 : Définition des paramètres de l’analyse
Le fichier récupéré sera à mettre dans un dossier d’analyse dédié (qui sera à préciser par la suite). Dans ce dossier d’analyse, un fichier de parametrage JSON sera à créer : analyse_parametrage.json
Ce fichier doit contenir les infos suivantes :
- Le nom du fichier de données
- Le type de fichier (ici il s’agit de fichier csv) (le format tsv est aussi possible, fichier texte avec la tabulation comme separateur)
- Le nom de la colonne pour le session id (id de visite)
- Le nom de la colonne pour le hit number (position du hit dans la session)
- Le nom de la colonne pour la variable étudiée (cette variable s’appelle nom_col_page)
- La valeur à étudier (par exemple si on travaille pour les pages, il s’agit de la page de départ ou de la page d’arrivée ciblée) (cette variable s’appelle page_a_etudier)
- Le sens de la sequence à étudier (les chemins après une page donnée, ou avant) (les valeurs possibles sont brut, normal, inverse)
- Le nombre de niveaux qu’on veut visualiser (le nombre d’etapes dans les sequences)
- Le nom de la colonne créée qui contiendra les volumes de sessions (en plus de la visualisation en soleil, un fichier de compilation des données est créé) (il s’agit de la variable resultat_nom_colonne_volumes)
- Le nom du fichier html généré pour la visualisation (il s’agit de la variable resultat_nom_fichier_html)
Exemple de fichier JSON :
{
"fichier_donnees_nom" : "pa_donnees.csv",
"fichier_donnees_type" : "csv",
"nom_col_session_id" : "ID Visite",
"nom_col_hitNumber" : "Position",
"nom_col_page" : "Page",
"page_a_etudier" : "/Boutique/Panier",
"sens_sequence" : "inverse",
"nb_niveaux_pages" : 15,
"resultat_nom_colonne_volumes" : "sessions",
"resultat_nom_fichier_html" : "R_sunburst_file"
}
Lorsque ce fichier JSON est créé. Il s’agira alors d’executer un script R en lui passant 2 informations :
- Chemin d’accès au dossier des scripts
- Chemin d’accès au dossier de l’analyse
Ceci est expliquée à l’etape suivante.
Etape 3 : Transformation des données
Lors de cette étape, il s’agira de lancer l’execution d’un script R qui va générer automatiquement la visualisation.
Cela se fait en 3 lignes de commandes dans Rstudio :
dossier_des_scripts_r <- choose.dir(caption="Selectionner le dossier des scripts")
chemin_script_master <- paste0(dossier_des_scripts_r,'\\','Sunburst_script_master.R')
source (chemin_script_master)
Ce code va ouvrir une fenêtre pour sélectionner le dossier des scripts R (pour pouvoir executer ensuite le script master). Et lors de l’execution des scripts, une deuxieme fenêtre s’affichera pour sélectionner le dossier d’analyse (pour pouvoir lire le fichier de paramétrage JSON).
Lors de l’execution du script les grandes étapes qui sont réalisées sont les suivantes :
- Un script « master » coordonne les tâches qui sont dans d’autres scripts selon le travail à réaiser
- Un travail de recuperation du hit de la variable à etudier pour chaque session, selon le sens de la sequence paramétré
- Un travail de structuration des sessions par sequences (etapes 1, 2, 3, etc) avec prise en compte des fins de sequences (si une session a moins d’etapes que le nombre d’etapes paramétrées à etudier).
Cela donne comme résultat un fichier où chaque ligne correspond à une session et chaque étape correspond à une nouvelle colonne. Ce fichier est généré dans le dossier d’analyse. Et il sera utilisé par le script de generation de la visualiation dont on va parler dans l’étape suivante.
A savoir : lors de l’execution des scripts, si une erreur survient, cela peut venir de l’absence des librairies necessaires dans Rstudio. Il s’agirait alors de bien télécharger les librairies dans Rstudio (celles présentes dans les scripts R avec la reference library(xxx) ).
Etape 4 : Génération de la visualisation en soleil
Lors de l’execution du script, la visualisation est générée grâce à des librairies R mises à disposition par la communauté R :
- sunburstR
- d3R
Ces librairies permettent de convertir le fichier des données sructurées en un arbre JSON et de generer un fichier HTML qui contiendra la visualisation, ainsi que l’arbre JSON sur lequel elle repose.
Cette étape peut prendre du temps. Pour cela, une mécanique est mise en place pour que le script puisse tourner en arrière plan. Lorsque la visualisation a fini d’etre générée, une fenetre s’affiche alors au premier plan pour informer l’utilisateur, ce qui permet de travailler sur une autre tâche sans avoir à suivre l’execution du script.
La visualisation générée
La visualisation est disponible dans le dossier d’analyse (un dossier Exports est disponible avec les visualisations et le fichier structuré des données). Le sunburst est visible avec le fichier HTML qui peut être partagé (avec tout le contenu du dossier Exports).
La visualisation est interactive :
- En cliquant sur les différents niveaux pour zommer (in/out)
- En passant la souris sur les elements du soleil pour voir les données (nom de page, volume de sessions correspondantes, ratio en %).
Je mets ci-contre le lien vers la visualisation en soleil (générée avec les fausses données) :
https://www.webanalytix.fr/Sunburst-R/pa_sunburst/R_sunburst_file_pa_d2b.html
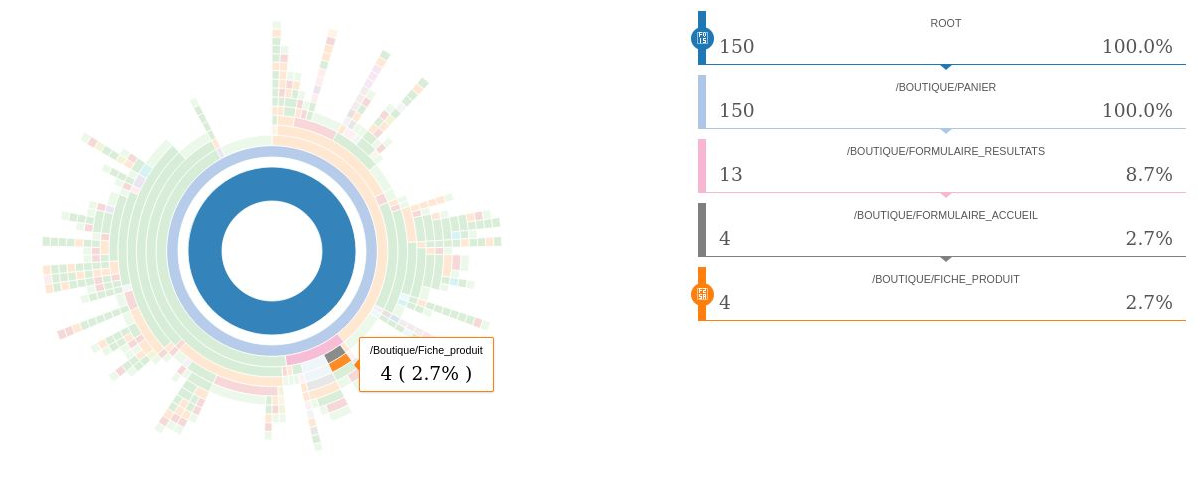
Pour lire le sunburst : Le sunburst a été paramétré pour montrer le parcours (inverse) menant à la page Panier. Le rond central correspond à la page Panier. Et les autres cercles montrent les pages précédentes. Quand un parcours contient peu d’etapes, il se termine par une etape FIN (si il n’y a pas FIN c’est qu’il faut plus de niveaux pour afficher le parcours en entier). On constate avec ce sunburst que la majorité des parcours qui amenent aux paniers passent par les pages de liste de produits. Il y a également 7,3% des sessions qui commencent directement sur le panier (la page precedente étant FIN) et 5,3% des sessions qui n’ont vu qu’une seule page qui était Fiche Produit avant d’arriver au Panier.
Je mets ci-dessous les liens vers le fichier de données de départ (fausses données) :
Je mets ci-dessous le lien vers les scripts R (à executer dans Rstudio via les 3 lignes de commande données à l’étape 3) :
Pour + d’infos :
– https://github.com/timelyportfolio/sunburstR
– https://bl.ocks.org/kerryrodden/7090426
{kind=link}
{kind=link}